
How to Size Your Kafka Tiered Storage Deployment
How KIP-405 let's you pay 10x less for storage, use less memory, deploy fewer instances, AND get better performance 🔥


I’m not joking when I say Tiered Storage is a revolutionary Kafka feature.
So far, we have covered a lot of detail about it in our blog series:
16 ways Tiered Storage makes Kafka simpler, better and cheaper
a deep dive into the internals - two pieces about how the write and metadata paths work, as well as reads and deletes
In this final part of the series, we will take you through a comprehensive cluster sizing walkthrough.
We will dive deeply into all the (technical) factors one has to consider when sizing their cluster, and see first-hand how much Tiered Storage simplifies everything, while also dramatically lowering costs.
📝 TL,DR;
This is a 7500 word article. It is jam-packed of incredibly interesting technical nuggets, but takes time to read.
We have provided two convenient TLDRs of it:
✅ a human-made bullet-point recap
🤖 a prompt to feed into your AI Chatbot of choice and ask questions on 🦾
Both are available at the end - just scroll to the bottom!
Here’s a footnote shortcut1
If you want to learn → grab a coffee and let’s dive in. ☕️
How Tiered Storage Saves You Money (and Trouble) 💸
In our previous piece, we covered the 3 main ways Tiered Storage saves money:
3-9x lower storage costs because object storage is simply a cheaper storage medium
Lowered instance costs when storage was a bottleneck and forced you to deploy more instances than necessary. (common)
More flexibility in instance types chosen, allowing one to vertically scale and get more bang for each buck
To illustrate the example best and most practically, we will assume a Kafka deployment that uses standard configurations used throughout commonly-seen benchmarks:
100 MiB/s of produce throughput
300 MiB/s of consume throughput
7 days of retention (the default)
a replication factor of 3 (the default)
highly available - spread across 3 availability zones
We will dive into the costs in detail in AWS. To calculate the costs, we will use my neutral cost calculator (AKalculator) and be transparent about what parameters it chooses.
The Baseline
Let’s set up the cluster without KIP-405, so we have a base to compare against.
Compute: 19 brokers running r7i.xlarge2 instances
Splitting the workload evenly means each broker accepts ~5.25 MiB/s of producer writes and serves ~15.8 MiB/s of consumer reads.
The calculator chose 19 simply because our storage requirements don’t allow us to provision any less!
16 TiB is the max EBS HDD size, and we need 19 of those given our disk capacity requirements.
It’s worth noting one could choose 21 brokers here so they’re evenly divisible by 3 and therefore spread evenly across the availability zones, but we will opt for a simpler and cheaper calculation.3
Storage: 19 16 TiB HDD EBS volumes
The calculator recommends sc1, but we will calculate with both sc1 and st1 for fairness.
Network: 266.66 MiB/s of traffic crosses zones and is charged data transfer fees by AWS:
66.66 MiB/s of producer traffic crosses zones (2/3rds)
200 MiB/s of replication traffic crosses zones (2x the produce).
Let’s assume the consumer traffic uses fetch from follower (KIP-392) and therefore never crosses zones (private IPs must be used to realize the savings)
Before we start comparing costs, allow me to explain what motivated the choices here and why they’re reasonable.
🤔 First Things First - The Disk
For disk-based systems like Kafka, the storage medium can have a massive impact on the overall cost of the deployment.
A setup with 7 day retention at 100 MiB/s average producer traffic means our cluster will have 57.68 TiB of data to store before even counting replication. After replication, it will be 173.03 TiB.4
That’s a lot of data!
Choosing the right setup is paramount to achieving the most cost-efficient deployment. There are two main concerns one has to get right here:
Disk Performance - i.e. the IOPS and latency
In the cloud, it’s the disk type that usually dictates this. Different disk types offer vastly different performance guarantees, at vastly different costs.
Disk Capacity - i.e the amount of free space buffer we provision
In the cloud, it’s the provisioned disk size that dictates this.
Let’s explore the concerns with both.
Disk Performance
Why is Kafka Fast?
Kafka’s latency is heavily dependent on the storage it uses. By design, Kafka was made to run on HDDs. Its idea was to run on inexpensive commodity hardware, scale horizontally and allow for crazy high throughput.
The way it achieved fast latency on slow, inexpensive hardware is by running without `fsync`5 - i.e it doesn’t synchronously flush the data to its physical drive.
Essentially, for a brief moment in time, it’s implicitly storing the write in RAM across the three replica nodes. In practice, most of the time Kafka returns a response before the data actually gets persisted to disk. To achieve durability, Kafka relies on the fact that the data is replicated in three different availability zones in that intermediate amount of time.6
The linear nature of the log data structure Kafka uses allows the OS to efficiently batch writes as it asynchronously flushes data from the page cache to the disk. This makes Kafka very IOPS efficient, which allows it to run on inexpensive HDDs that are usually very low in terms of IOPS.
In the end, through both of these means, Kafka squeezes out great performance from the HDD while keeping latencies low.
How much IOPS do we need?
IOPS are tricky, because they depend on various factors like the number of partitions, the amount of historical consumer reads that read data outside of page cache, etc.
To keep things simple, we will take the following conservative assumptions:
25% of all consumer traffic is historical and forces Kafka to read from the disk
the size of a Kafka IO is 128 KiB
Both of these are very conservative estimates:
Kafka can be expected to achieve 1 MiB IOs, especially with AWS’ EBS HDDs which have additional proprietary IO merging capabilities. The IO size we use is 8x less than that. We choose it to prove a point that we’re way above the limit and do not need SSDs.7
The amount of historical traffic is also high at 75 MiB/s (25% of 300 MiBs).
The Performance Question - st1s or sc1s?
AWS offers two kinds of HDDs in EBS - sc1s ($0.015/GiB) and st1s ($0.045/GiB). The 3x difference in price comes because of a difference in performance:
SC1s give you 12 IOPS per TiB of provisioned capacity up to a max of 192 IOPS
ST1s give you 40 IOPS per TiB of provisioned capacity up to a max of 500 IOPS
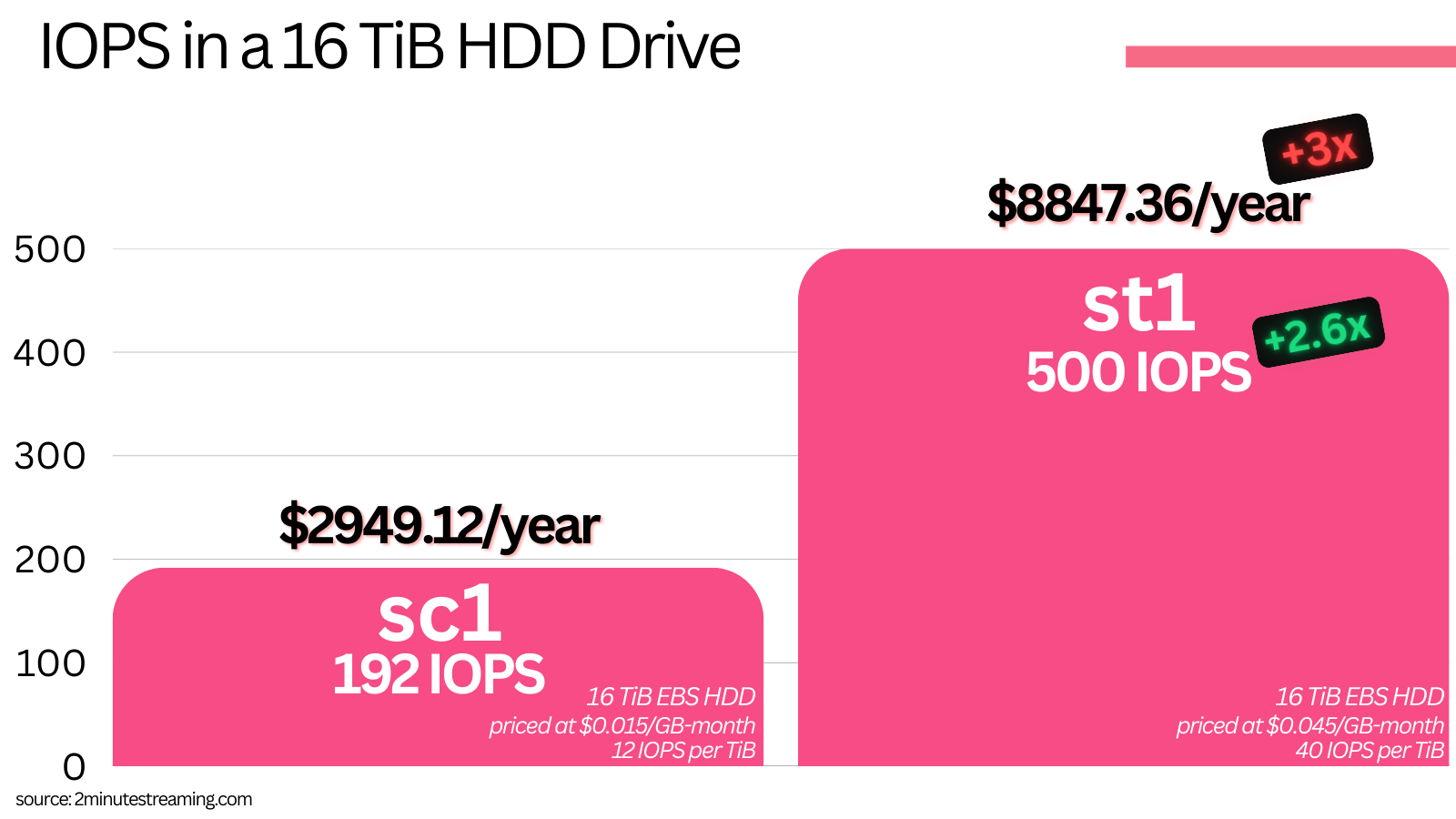
Note that for these HDDs, the actual IOPS given by AWS is counted in MiB/s, because it assumes every IO is 1 MiB. This is somewhat of a fair assumption by them, because as mentioned their software additionally tries to coalesce sequential IOs.
sc1 is all you need
With our nineteen 16 TiB sc1 drives, we get 192 MiB/s max capacity per broker - or said otherwise, 192 IOPS.
On average, each broker in our setup accepts 5.25 MiB/s of new data from the producers, as well as 10.5 MiB/s of replication from other brokers8. This results in ~15.75 MiB/s of disk writes.
The broker also on average serves 15.75 MiB/s of reads to consumers, and 10.5 MiB/s of replication reads sent to other follower brokers. Because the replication reads are always from the tail of the log, we rightfully assume it all comes from the page cache. As we mentioned earlier, 25% of the consumer traffic is expected to be historical and read from the disk - so we add 3.95 MiB/s of disk reads.
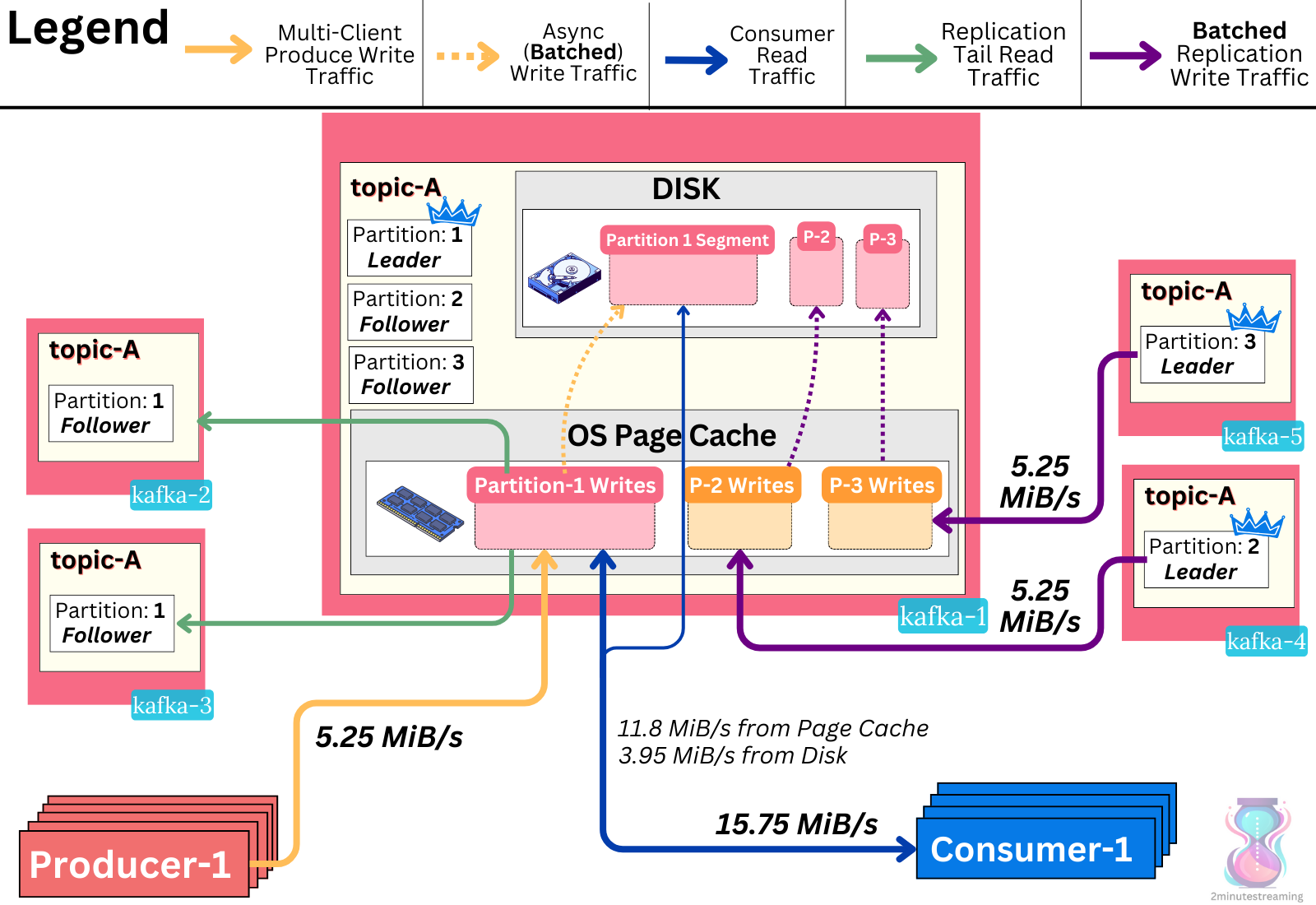
A total of 19.7 MiB/s disk operations (read+write) take place on a broker.
That’s 158 IOPS according to our conservative estimate of 128 KiB IOS (20173 KiB/s / 128).
The brokers have 192 IOPS, so this should work. Even in this conservative estimate (overcounting IOs by 8x), no more than 82% of the IO capacity is used up.
While sc1s can be prohibitively slow for most use cases, our specific storage-bottlenecked setup makes them viable. The math works out because:
sc1s’ performance scales as you add more disk capacity
brokers store a lot of data relative to what they take in - 16 TiB of storage to ~20MiB/s of disk operations
In any case, these assumptions can fall short in cases where a lot of partitions are used, more historical reads come at once, traffic spikes up, or even if a lot of consumer offset commit requests come in. It depends on your risk appetite.
Other clouds also don’t provide a low-cost HDD option, so to keep things totally fair:
✅ We will calculate the cost with the more performant st1 type too.
Disk Space
Another massively important variable is the amount of free space. Because we are managing the disks ourselves, we have to similarly manage their capacity. If the disk runs out of space, the whole broker will go offline and risk a domino cascade.
The choice of the right amount of free buffer space is complicated, but the general rule of thumb is that it should give you enough time to react during incident scenarios so as to avoid it running out of disk under all circumstances.
In our example, the disks use 40% free space. We find that this still is a very conservative number. It results in 6.4 TiB of free space from our 16 TiB disks.
Recall that we get a total of 15.75 MiB/s new data write throughput per broker. Even if the cluster’s throughput unexpectedly doubled and consistently stayed that way for whatever reason, it would still take 5 days to fill the extra free space - giving operators ample time to react.
One could definitely provision less free space and save more, without materializing any greater risk.
Make Sure You Get It All Right 😥
Here's the takeaway so far:
✅ Cost comparisons are packed with niche and subtle intricacies.
One miscalculated variable throws off everything.
Some calculators, like Confluent Warpstreams’, assume an absurd amount of free space (60%) and choose to use high-cost SSDs (gp2, not gp3) without Tiered Storage.
Such decisions heavily penalize Kafka’s cost and estimate an unnecessarily-high cost burden. Here is a quick chart that shows how vastly different the storage end cost can end up, depending on the disk type and free space config you set, using our example workload. (interactive graph)9
To reiterate, we will choose a healthily conservative 40% free space number and show both sc1 and st1 types of volumes to be maximally fair.
SSDs would be massive overkill for our low per-broker throughput case here.
Baseline Costs
With that large disk caveat out of the way, we can finally dive into the actual baseline costs.
You can already see that we had a lot of intricacies to consider before simply choosing the disks. Thankfully, with Tiered Storage our choice becomes much more straightforward, more performant AND cheaper!
Without tiered storage, our baseline costs are:
Compute: $3672 per month for 19 r7i.xlarge instances at $0.2646/h
Data Transfer: $13,500 per month for 659.16 TiB of cross-zone traffic charged at $0.02/GiB (266.66 MiB/s of cross-zone traffic for 30 days)
Storage: $4,430 or $13,289 per month, depending on the disk chosen
We have 173.03 TiB of post-replication data to store and we want to sustain 40% free disk space. That’s around 288.38 TiB (295301 GiB) of total disk capacity to provision.
st1s are charged at $0.045/GiB, so the total cost would be $13,289 a month.
sc1s are charged at $0.015/GiB, so the total cost would be $4430 a month.
Here’s an interesting observation - depending on the disk configuration, the storage costs may end up significantly higher than the data transfer costs!
🤔 When we choose st1s with 40% free space, we get storage costs equal to the data transfer costs
❌ If we were to opt for 60% free space with st1s, it would cost $19,933 a month - 50% higher than the data transfer fees.
🤯 If we were to use the WarpStream calculator values (60% free space with gp2s), it would cost $44,295 a month - 230% higher than the data transfer fees.
These numbers only assume the default retention time of 7 days. Were one to opt for anything higher, the difference grows much larger.
I illustrate this to prove a point:
✅ Storage dominates Apache Kafka costs without Tiered Storage.
Tiered Storage to the Rescue
As we covered earlier, Tiered Storage has many, many benefits.
That being said, the most impactful one in our context here is the cheaper storage:
(Fixed & Low) Storage Costs
In the calculation above, we paid:
$0.015/GiB to $0.045/GiB for EBS storage
Accounting for replication, this ballooned to $0.045/GiB-$0.135/GiB per GiB of produced data.
Accounting for the free space on top of the replicated data, it soared to $0.075/GiB-$0.225/GiB per GiB of produced data.
With S3, the cost for this is much simpler (and lower!) - $0.021/GiB-$0.023/GiB.
Nothing more. You aren’t paying for replication. You aren’t paying for free space.
The data is replicated internally and free space is kept, but this is baked into the cost. We only pay for what we visibly store.
The total storage cost is therefore our pre-replication data (57.68 TiB) times the price - $1358 a month.
The pricing is tiered and depends on the amount of usage, but if your organization is storing more than 500TB in S3 - you can count it as $0.021/GiB - i.e $1240 a month.
What About the API Costs?
S3 does have extra associated costs with its API usage.
PUT cost $0.005 per 1000 requests, or $5 per 1 million requests
GET cost $0.0004 per 1000 requests, or $0.4 per 1 million requests (12.5x cheaper)
Those costs are negligible in the context of Kafka, though. Here’s why:
1. PUT Cost
Kafka only tiers non-active segments, and with Aiven’s open source plugin, it tiers via multi-part PUT uploads at a size of 25 MiB per PUT (configurable).
Our 100 MiB/s of new producer data is therefore equivalent to 4 S3 PUTs each second, the only difference is they’ll be executed asynchronously later.
That amounts to 10,517,217 PUTs a month - $52.6/m.
2. GET Cost
The GETs are even more trivial (they’re 12.5x cheaper).
Kafka will GET from the remote store when it’s reading data which is not present locally. As we established earlier - we assume that’s 25% of all consumer traffic.
75 MiB/s of cluster-wide read traffic will need to be served from the remote store. The configurable GET chunk size - is 4 MiB. That’s around 18.75 GETs each second.
We can round it to 20 for simplicity, amounting to 51,840,000 GETs a month - $21/m.
There are a few extra negligible GET/PUT calls from fetching indexes and etc, but we need not account for them because they’re generally insignificant.
In total, our API costs are around $74/m.
Our Baseline Tiered Storage Cost
We have gone through our base, fixed S3 costs. We have $1240-$1358 for the storage (let’s take the average to be conservative - $1299) and $74 for the API - a total of $1373 per month.
What’s left are variable costs that can be tweaked depending on the configuration:
local storage
instances
Local (Broker) Storage
Some amount of data still needs to be kept locally on disk!
Usually, the rule of thumb here is - the less that’s stored locally, the better!
As we covered in a previous piece, with less local state on the brokers, cluster maintenance operations become substantially easier:
Partition reassignments become 7-14x faster
Cluster expansion becomes much faster
Small disks are cheap and make it affordable to run very high performance SSDs, reducing perf problems
How Much Data Should We Provision?
Let’s assume our local retention time is set to 3 hours. The only implication this setting has is that consumers fetching data older than 3 hours will need to fetch it through the remote store.
In our last piece covering reads, we showcased how prefetching with caching can lower the latency of remote reads to something comparable to local reads. In the end, there doesn’t appear to be much downside to setting local retention to a relatively very low value.
As for the free space - let’s assume we want to keep 12 hours worth of space for data. The purpose of keeping so much free space is so that we buy reaction time for our on-call engineers in the event of an incident where the remote storage service becomes unavailable.
Imagine the following example:
we are running a Kafka cluster on AWS with 3 hours of local retention, and 12 hours worth of spare space.
S3 becomes completely unavailable for a full day (24hrs).
our disks will need around 24 hours worth of space to accommodate all the data, but they only have 18 hours.
Without any intervention, the brokers would keep accumulating local data until they completely run out of space and break.
we need to do something!
It’s worth noting that such S3 downtime has never occurred throughout its history so far. The longest downtime ever was around 4-5 hours in us-east-1 on February 2017, considered one of the most impactful AWS outages of all time. We can assume our cluster won’t experience a 10+ hour outage, especially if it’s not located in us-east-1.
Regardless, were the remote store unavailable for such a prolonged period, the broker would keep accumulating local data until it runs out of space. How we deal with this depends on the type of storage we leverage:
EBS (or cloud’s equivalent) - an instant one-click resize solves the incident.
These disk solutions offer an instant (within minutes) disk resizing capability. Resolving the incident is as simple as pressing a button to increase the disk capacity to something larger.
When the remote store recovers fully, the broker will tier everything back up to it and go back to using less disk space.
Local instance storage - add new brokers and reassign partitions.
This is more involved. The local instance storage is fixed and cannot be expanded, so we add more instances. When we add new brokers, they’re empty, so we need to reassign partitions from the older brokers to the new ones. This can take extra time and needs to be pre-planned more carefully.
Since local instance storage tends to be cheaper, one could afford to run with larger headroom for the same price as EBS.
Shopping Around for SSDs
With 100 MiB/s of produce and 3 hour of local retention, we now have to store 1.03 TiB of data pre-replication and 3.09 TiB of data post-replication. Accounting for the 12 hours worth of free space, we end up with a total disk capacity of 15.45 TiB.
✅ That’s more than 18x less than our previous 288.38 TiB number!
At such low total capacity, we can begin cost-effectively shopping around for SSDs.
Seemingly from the table above, SSDs give us a ton more IOPS than HDDs. But there is one catch - the IO size for SSDs in AWS is limited at 256 KiB, whereas for HDDs it’s limited at 1 MiB.
While important in practice, this doesn’t concern our calculation because we conservatively already assumed that the size of a Kafka IO is 128 KiB earlier.
The only EBS drive worth considering for our use case is the gp3, priced at $0.08 per GiB. Every gp3 drive comes with a baseline number of 3000 IOPS and a max 125 MiB/s of throughput, regardless of its size. The two different limits means you’re bottlenecked by whatever you hit first:
500 IOPS at 256 KiB each? You hit the 125 MiB/s throughput limit (Kafka-type workloads)
3000 IOPS at 16 KiB each? You hit the 3000 IOPS limit. (DB-type workloads)
gp3s separately allow provisioning extra IOPS at a cheap price of $5/m per 1000 IOPS, and $4/m per 100 MiB/s of throughput.
Our total workload is 300 MiB/s of disk writes. Divided by our conservative 128 KiB IO assumption, it gets to 2400 IOPS.
A critical thing with Tiered Storage is that we can assume there are no more disk reads because all historical data is older than three hours and is served from S3.10
What becomes apparent now is that the table has flipped!
The sc1s and st1s HDDs suddenly give us way too little IOPS.
We are no longer bottlenecked on storage - we are bottlenecked on IOPS!
It is now a valid time to completely discard HDDs. 👋
Not only are they less performant, but they’re also at least 3 times more expensive for the same amount of IOPS compared to SSDs.
gp2 vs gp3
At this point, we’re beginning to sweat the small stuff. The cost between both is close enough that it’s not going to make a large impact on our deployment either way. For completeness, we will quickly overview both:
gp2: offer 3 IOPS per GiB and a tiered throughput. Drives above 334 GiB can deliver 250 MiB/s of throughput.
gp3: offer up to 1000 MiB/s of throughput, paid separately.
In almost every case, it makes sense to opt for gp3s. They’re the new generation and are cheaper.
Simply running with the baseline drive numbers and the minimum number of disks (3), we would get 9000 total cluster IOPS and 375 MiB/s total cluster disk throughput.
To be extra conservative, let’s provision an extra 20,000 IOPS (at $100 per month) and an extra 600 MiB/s of throughput (at $24 per month).
It’s so cheap that it doesn’t matter anyway.
Let’s go with gp3s.
Total Storage Storage
We now have our total cost of storage in the cluster:
✅ a total of $2763 per month.
$1390 for the EBS
$1373 for S3
Our previous cluster had its storage cost between $4,430 (with slow sc1s) and $13,289 (with st1s).
For a 1.6x-5x lower cost, we get both better performance and easier operations.
It’s very rare that you can have your cake and eat it too, but Tiered Storage gives you just that. 🍰
Broker Instances
Now we get to the interesting bit! This is a very nuanced second-order effect - Tiered Storage gives us so much flexibility on the instances, that we can spend a few blog posts discussing that alone.
We previously had 19 r7i.xlarge brokers for a total of 76 vCPUs and 608 GiB of RAM, costing us $2394 per month. The reasoning for 19 was simple - we needed enough instances to attach 16 TiB of EBS disks to. As mentioned in the footnotes, the 4 vCPU r-series is the commonly recommended one for running Kafka with EBS.
With Tiered Storage, we can now afford to run a cluster as small as 3 brokers. Since storage is no longer the bottleneck, only throughput per broker is limiting us.
Small clusters are easier to operate and generally more cost efficient. We have to take care to not go too small because that has drawbacks too11.
We will opt to not go below a minimum size of 6 brokers.
Let’s shop around and compare instance types now!
Here are 3 options:
Questioning Old Assumption - how much vCPU & RAM do we need?
✅ As our system has changed with KIP-405: Tiered Storage, so should our assumptions:
Do we actually need 600 GiB of RAM to serve a 100 MiB/s workload?
This topic can be its own blog post, so in the interest of being concise we will need to oversimplify some things and skim over it.
RAM: Kafka uses RAM in two ways mainly, one for caching (usually outside the JVM - e.g pagecache) and another for its own operations (the heap).
Kafka can be assumed to use from 2 GiB to 6 GiB of heap, usually on the lower side.
The rest of the RAM, per broker, we can attribute to (page)caching
vCPU: This is very tricky to model and depends on many factors12
We will go ahead and conservatively assume that 1 vCPU can support both 4 MiB/s of producer throughput and 12 MiB/s of consumer throughput at once.
How much vCPU?
Our cluster experiences 100 MiB/s of produce and 300 MiB/s of consume, which means that around 25 vCPUs will be enough to support the workload. Assuming we want to run at around 50% capacity to account for headroom, we should aim to provision around 50 vCPUs.
How much RAM?
Assuming we have 6 brokers, and conservatively accounting for the worst case usage of 6 GiB of heap per broker, we need 36 GiB of RAM for the brokers to operate.
The rest is a matter of how much we want to cache. At 100 MiB/s, the total writes that brokers receive is 300 MiB/s when accounting for the 3x replication. We only need to account for caching the data for at most 5 minutes, because we assume that no consumer or broker will experience consumption lag greater than that (outside of incident scenarios).
89 GiB of RAM will be enough to hold the last 5 minutes’ worth of writes within a cluster.
We have 75 MiB/s of historical consumer reads that require remote storage reads, so it’d be good to cache them aggressively too in order to ensure low latency. Storing 5 minutes worth of that would require just 22 GiB of memory.
In the end, we arrive at 111 GiB of cluster-wide memory in order to comfortably cache all the data we believe will be needed.
Just in case - let’s add 50% extra as a buffer - 167 GiB.
The careful reader will have noticed:
🤔 This is quite the far cry from the 608 GiB of RAM we previously had provisioned.
What’s the deal, how come we need so little now?
HDD & Cache Sensitivity
The good thing about HDDs is their cost. The bad thing about HDDs is their limited IOPS.
As we had said in our first Tiered Storage piece:
IOPS HDDs have improved exponentially, but not in all dimensions. There are three main reasons they’re disfavored today:
Their seek latency is high (speed is physically limited)
They’re physically fragile.
Most importantly - they’re constrained for IOPS.
While their capacity has grown multi-fold throughout the years and their price has decreased alongside - HDDs have been stuck at around 120 IOPS for the last 2 decades.
✅ The reason pre-KIP-405 Kafka had to be deployed with high-memory instances was to prevent hammering the disk as much as possible.
The ample memory allows the OS to:
use less IOPS for writing data - by batching writes to the disk
do not use disks for reads - cache as much as possible so as to prevent reads taking precious IOPS too
Were Kafka to use too many IOPS, the disk IOPS could get exhausted. That, in turn, could cause a cascading negative effect of client latencies blowing up and brokers falling behind with replication, eventually leading to unavailability.
Such a cascade can be devastatingly simple to trigger—one heavy historical workload can light the fuse on a pagecache bomb. Historical reads request data from the start of the log, which isn’t in the pagecache. This trashes what’s already in the cache, and a vicious cycle of competition for IOPS and pagecache begins between the historical and regular tail consumer workloads. 😰
With high performance SSDs this is no longer a concern!
Reads can safely be served from disks - they’re unlikely to exhaust the IOPS because SSDs have plenty, and the latencies are still likely to remain low because SSDs are fast!
High volume writes don’t need to be batched - they can use a lot of IOPS and still perform fine. The large amount of IOPS would not visibly impact the disk nor its latency, as long as it remains below its (very high) capacity. There is therefore less need to use RAM in order to batch IOs.
In essence, the large amount of memory Kafka needed was a historical consequence from past deployment setups:
Because we lacked tiered storage, we had to store data locally.
Because we had to store a lot of data, we had to find the most cost efficient solution - HDDs.
Because these drives’ IOPS were very limited, their performance was very sensitive to disk pressure.
Because their performance was sensitive, we had to be very conservative with how much we cache so as to avoid pressuring them at all costs.
Performance is as much of an art as it is a science. Benchmarks are necessary to make a final decision. Nevertheless, undisputably, with Tiered Storage enabling use of performant SSDs cost-effectively, we have a significantly larger amount of leeway with our deployment setup.
New Requirements
We have arrived at our new system requirements:
167 GiB RAM (running with 5 minutes worth of cache, plus 56 GiB as extra capacity)
50 vCPUs (running at 50% CPU util)
To be extra conservative in this napkin math exercise, we can bump both by 30% just because. Let’s aim for 217 GiB RAM and 65 vCPUs. It’s an art. 🤷♂️
Now that we aren’t optimizing for memory, we can look at the general purpose m7i family of instances:
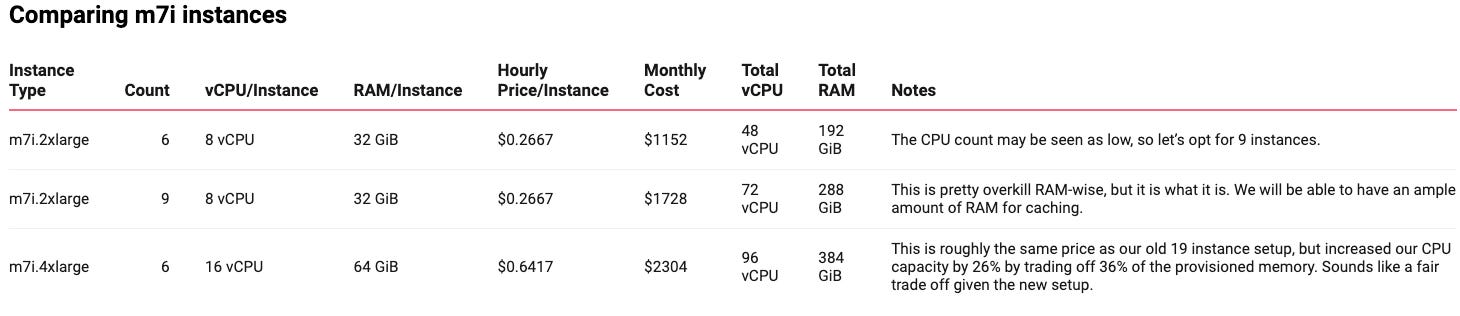
In any case, we can opt for the simple 9 m7i.2xlarge setup. With that, we have:
reduced our cluster size by 10 brokers 🥳
reduced our instance cost footprint by 30% 🎉 (from $2394/m to $1728/m)
Network ⚡️
Network can also be a bottleneck, and requires overview to ensure there is ample headroom - so let’s cover it quickly:
Brokers use network when serving produce requests (writes), replicating data both in and out, serving consume requests, and writing/reading from S3.
100 MiB/s of cluster-wide produce results in 300 MiB/s of total data coming into brokers for writes and replication, and 200 MiB/s going out of leaders for replication
300 MiB/s of cluster-wide consume results in 300 MiB/s of total data egressing out of brokers and into clients
75 MiB/s of said consume being historical results in S3 reads, which counts as broker ingress
Tiered Storage means roughly 100 MiB/s of data gets egressed to S3, although asynchronously
In the end, we have an ingress of roughly 375 MiB/s and egress of roughly 600 MiB/s.
How much network do our instances give us?
It’s unclear, because all the values AWS published are “up to”.
That being said, the largest m7i - the m7i.8xlarge - guarantees 12.5 Gigabits per second of networking. That’s around 0.39 Gigabits per core, which is 46.5 MiB/s.
If we apply that linearly to our m7i.2xlarge, we reach 372 MiB/s of network capacity per broker (8 cores). Summed up, it’s 3348 MiB/s for the whole cluster. It is unclear if these guarantees are duplex or not.
Nevertheless, our duplex networking requirements are a measly 975 MiB/s. 3348 MiB/s is more than 3 times that capacity.
A bottleneck in networking is therefore very unlikely to be an issue.
Questioning Old Assumptions #2 - do we need EBS?
To leave no stone unturned, we need to consider local instance storage.
The main drawback with instance storage is the fact that it’s ephemeral. If an instance is lost, it will come up with an empty disk. This can be semi problematic in two main scenarios:
data loss: if producers use acks=1, a broker VM may acknowledge a request and fail before the data is replicated, therefore 100% losing data. This is imperfect, but expected given the acks settings. Although less likely, the scenario could happen with EBS too. The only difference is that the likelihood of a single node failing is higher than the multiple backing EBS drives failing.
ephemeral data: if the instance is stopped, if the broker pod gets moved to another instance, or if the instance crashes - the local data gets erased. This results in the new broker coming up with an empty disk and having to replicate everything from scratch to catch up. This places extra strain on the cluster and its disks.
The main concern is the ephemeral data. With our 9-broker setup and 3 hour retention, we can expect a routine failure to require a new broker to replicate 352 GiB of data.
If split evenly, the failed broker would need to read 44 GiB from each other broker.
If it reads at 80 MiB/s per broker, it will require a total of 10 minutes to recover.
Thankfully, since our brokers each have around 267 MiB/s of spare network capacity, more spare vCPUs and cheap SSDs with ample performance guarantees, this extra throughput is unlikely to cause a performance dent in the cluster.
The only result will be that rolling restarts will take some time.
Let’s quickly shop around for instances with local storage.
It’s natural to first consider the m6id.2xlarge instance - it’s the closest to our m7i.2xlarge. The only problem with the m6id is that its disk is too small - it has a 474 GB local SSD. To meet our total disk requirements (including the free space buffer) - we’d need 34 of those instances.
Shopping further leads us to the i3.2xlarge storage-optimized instance. It has 1900GB local NVMe SSDs, which means 9 such instances would cover our needs. Let’s consider it more seriously with a checklist:
Is Local Storage Worth It?
With these 9 i3.2xlarge instances, our total local disk + instance cost would be $4101 a month.
Let’s compare that with our EBS setup:
The main difference we see here is that of the disks and RAM.
The local storage has a lot more IOPS capability at 4 KiB, but it’s unclear how it performs with large sequential writes (that Kafka uses). EBS is at least clear in its documentation - its max IO size is 256 KiB and there is a throughput limit on the disk.
Using Up Our Budget
With a $1000/m difference between gp3 and local storage, we could buy up a lot of extra gp3 resources.
If you recall, each gp3 gave us 125 MiB/s of throughput and 3000 IOPS at baseline. Cluster-wide, this resulted in 1125 MiB/s and 27000 IOPS.
We bought an extra 20,000 IOPS and 600 MiB/s throughput, leaving us at 1725 MiB/s and 47,000 IOPS cluster-wide.
Our bottleneck right now is the throughput limit on the drive.
To max out our 47,000 IOs at our conservative 128 KiB block size - we need 5875 MiB/s of total throughput allowance. This means we need to buy up an extra 4150 MiB/s worth of throughput. At $0.04/MiB, that costs a measly $166/m.
We’ve got $834 left to go!
Let’s buy 83,333 IOPS. To match that in throughput (assuming 128 KiB IOs) - we have to buy 10,417 MiB/s of throughput.
This will cost us $416.6 for the IOPS and $416.68 for the throughput. It lines up nicely!
We have now exhausted our $1000 budget. Let’s see what it got us!
Drawing the Line
This blog post has been long enough. We draw the line here and will now compare our 3 possible KIP-405 solutions:
I wasn’t kidding when I said that Tiered Storage gives you a ton of flexibility!
It’s worth noting that we haven’t yet exhausted the instance choice:
We didn't even consider Graviton instances, which are claimed to give 30-40% better cost-performance benefits.
Even AWS’ MSK service (with its extra margin on top) offers 29% more throughput for 24% less price.
As for these instances - the decision seems straightforward.
The $3118/m m7i.2xlarge instances with minimal EBS addons seems like the most common sense choice:
it is comfortably above all of our requirements 👌
it is easiest to operate (no data ephemerality to deal with) 🙂
it comes at the cheapest price! 💸
Final Comparison - before and after KIP-405
With all of this being said, I leave you with the final comparison:
As you can see, because we got the cost of everything down by so much in our optimized Tiered Storage setup - network costs began to dominate. They’re a whopping 3/4th of the total cost!
This is the reason why the next logical step for Kafka is to adopt the stateless, leaderless, diskless architecture (KIP-1150), which would allow it to drop all of that network cost down to $0.
In the end, for our workload of 100 MiB/s in and 300 MiB/s out at 7 day retention, a Tiered Storage gp3 SSD deployment can be 1.6x cheaper than a deployment that opts for st1 HDDs to store the data.
The relative cost savings (the 1.6x multiplier) scale up dramatically as data retention increases.
Not only that, but with boosted local performance from SSDs and massively reduced operational overhead (that’s offloaded to S3)—one thing becomes clear:
✅ High-retention retention Kafka workloads that skip Tiered Storage are bleeding money and burying their engineers in unnecessary operational work.
Summarized Takeaways (not AI)
Here are the takeaways we learned in this blog post:
💾 sc1 is all you need: We analyzed disk performance without Tiered Storage and discovered we can get away with the cheapest EBS HDD tier (sc1) if performance isn’t a top concern.
💾 Storage bottleneck: Lack of KIP-405 means disks dictate your deployment—we had to deploy 19 instances just to cover the max 16 TiB per instance.
💰10x cheaper storage: Due to replication and a 40% free space buffer, storing a GiB of data in Kafka with HDDs balloons to $0.075-$0.225 per GiB. Tiering it costs $0.021—a 10x cost reduction.
💰 Storage-dominated economics: We observed that depending on the disk type (st1 and up) and the free space buffer, storage costs can end up dominating your Kafka deployment costs. In our workload:
st1s with 40% free space gave us storage costs equal to the data transfer costs.
if we had opted for st1 witht 60% free space - the storage costs would have been 50% higher than the data transfer costs
if we opted for SSDs with 60% free space (as some calculators do) - it’d have been 230% higher than the data transfer fees.
Not to mention what happens if we increase retention time
💰S3 APIs cost peanuts: Worried about S3 API costs? Don't be. It’s just $74 per month total - 0.4% of all our costs.
🔧 IOPS become the bottleneck: With a 3-hour local data retention in Tiered Storage (plus a 12-hour free space buffer), we find that our setup becomes IOPS-bound, not storage bound. This makes SSD the most cost efficient solution.
📐 Conservative napkin math: Throughout this article, we used very conservative sizing guidelines. First-principles sizing (1 vCPU per a conservative 4 MiB/s produce + 12 MiB/s consume, 5-minute pagecache window) gave us baseline requirements of 25 vCPU and 111 GiB RAM.
We then added 50% as headroom, plus an extra 30% on top of that just to keep the napkin math conservative.
Result: 65 vCPUs and 217 GiB RAM for 100 MiB/s in and 300 MiB/s out.
💾 HDD tax on RAM: No tiered storage → storage bottleneck → cheap HDDs → low disk perf.
This forces you to provision massive amounts of RAM so as to avoid exhausting the disk’s IOPS, which risks cascading performance degradations.
🔍 Some subtle learnings:
Seemingly minor decisions (like disk free space percentage) and outdated choices (gp2 vs gp3, excessive RAM) can significantly inflate Kafka costs.
The critical role of IOPS
🔧 Fewer brokers: Tiered Storage makes 3-broker deployments viable. We went with 9 brokers—cheaper than before with zero performance sacrifice.
🔧 Network Capacity matters: Especially with Tiered Storage, networking can become a bottleneck. We verified our instances have adequate network capacity for the workload.
💾 Local NVMe not worth it: We evaluated local instance NVMe storage to see if we can find a better deal. While it offered higher raw IOPS for random operations, the extra cost and operational burden made it obviously not worth it for a Kafka deployment.
🏆 gp3s are awesome: by allowing us to separately purchase IOPS/throughput at a very cheap cost, a sample gp3 deployment got us to 50% more throughput than local SSDs - at the same cost.
AI Summary
Paste this gist text content into your favorite chatbot and ask it questions:
Quicklinks to chatbots:
If you disagree with anything said, please comment and let’s get to the truth
And, of course, if you aren’t subscribed - tune in so you don’t miss our next piece regarding KIP-392 - Fetch From Follower! 👀
this is just a shortcut so you scroll to the bottom tl,dr section
r7i is the latest in the r-series of Memory optimized instances, available in most if not all regions - 4 vCPU and 32 GiB of RAM; It’s generally recommended to run Kafka with plenty of memory. Confluent’s official recommendations are r4.xlarge - but for some reason they’re extremely outdated, as it’s a very old generation of the r instance type.
this lets us be extra conservative in the cost savings Tiered Storage offers
100 MiB * 60s * 60m * 24h * 7d * 3 (replication)
fsync (AKA flush) is an OS sys call that ensures data written to a file is physically stored on the storage drive. Without it, the OS batches the write in memory and flushes it later. If a broker is to crash before the physical write to the disk occurs, the data can be lost from that node. Kafka ensures the data is not lost by replicating the data to 3+ nodes before acknowledging the write (with acks=all). Kafka also supports recovery in case of local data divergence between nodes in the replication protocol.
the chance of 3 machines in different data centers failing at the exact same time is insignificantly low, despite some competitor vendors spreading FUD against fsync
we try hard to prove a point that SSDs are unnecessary because certain cost calculators and blog posts like fooling users about the real cost of Kafka.
10.5 MiB/s comes from 5.25 MiB/s producer traffic * 2; recall that follower brokers replicate (read) data from leaders and write it in their own disk
hover over the interactive graph to see the costs. It’s worth noting that the annual costs would even end up a bit higher, because here we count a month as 30 days and multiply by twelve for each month in the year. If we want to be entirely correct, we would compute months as 30.43 days on average.
in practice, of course, it depends on the workload. If it’s a workload that replays all data from start to finish, then at some point it will exhaust everything in S3 and start reading locally. This is more difficult to model without blowing up the complexity of this article even further, and is generally insignificant because of how many IOPS the SSDs have. (you’ll see soon)
e.g with just 3 brokers, one instance outage would omit 33% of our cluster’s capacity. If we were to get a node failure during regular rolling restarts/upgrades, it would lead to downtime for all of our producers because we’d go below the min.insync.replicas setting.
number of client connections, client configurations and behavior, number of partitions, underlying EC2 instance to name just a few