
From Stream to Table: Real-Time Analytics Made Simple with Kafka and Iceberg
From Apache Kafka® streams to SQL queries of Apache Iceberg™ in seconds—no complex ETL pipelines required

Why Streaming Analytics Can Be a Headache
You’ve got streams of valuable events flying through Apache Kafka®. You’ve got an analytics team begging for up-to-the-second insights. And yet…
Somewhere between those two worlds lives an overcomplicated, laggy, and headache-inducing pipeline.
Sound familiar?
Too many moving parts: custom ETL scripts, staging buckets, hand-tuned connectors
Delays: by the time your data lands in a table, it’s already “yesterday’s news”
Schema drama: keeping table structures in sync with event payloads
Operational overhead: wrangling multiple systems just to get a simple query result
A Clearer Path: Kafka + Iceberg with Aiven
This tutorial shows you how to stream data directly from Kafka into Apache Iceberg® tables in AWS S3, with Snowflake Open Catalog managing the metadata and Trino handling the queries.
The best part? It’s:
Open Source
Fully automated with Terraform
Ready to run with just a few commands
Fun to try (yes, really)
The GitHub Repo + Walkthrough Video
Everything you need is in the Aiven GitHub repo.
Inside, you’ll find:
Terraform scripts for AWS setup, Snowflake catalog creation, and Aiven service provisioning
Go producer code for streaming events into Kafka
Local Trino container setup for instant queries
Cleanup scripts so you can tear it all down with ease
And if you’d rather watch than read, I recorded a fun, quick video walking through the whole process step-by-step: Watch the walkthrough
Your Five-Step Adventure
1️) Prep Your Foundation
Spin up an S3 bucket for your Iceberg tables, create IAM roles and policies, and set up a Snowflake Open Catalog to keep everything organized. Terraform in terraform/aws_setup takes care of most of the grunt work.
2️) Spin Up Aiven Services
Provision your Aiven for Apache Kafka service, create a couple of topics, and add Kafka Connect with the Iceberg Sink Connector ready to roll — all automated in terraform/aiven_setup.
3️) Start Streaming
Use the included Go producer to send mock product data straight into Kafka. Every event gets transformed so keys aren’t lost when they land in Iceberg. You can download and add the following certs to a aiven-iceberg-tutorial/certs
Update the
const KafkaBrokerAddress = "<your-kafka-broker-address>" in main.goBuild and Run
go run main.go
4️) Query Instantly
Fire up the Trino container, connect it to your Snowflake Open Catalog, and start running SQL queries against your Iceberg tables — no extra ETL needed.
Navigate to Trino properties
cd trinocontainer/trino/etc/catalog
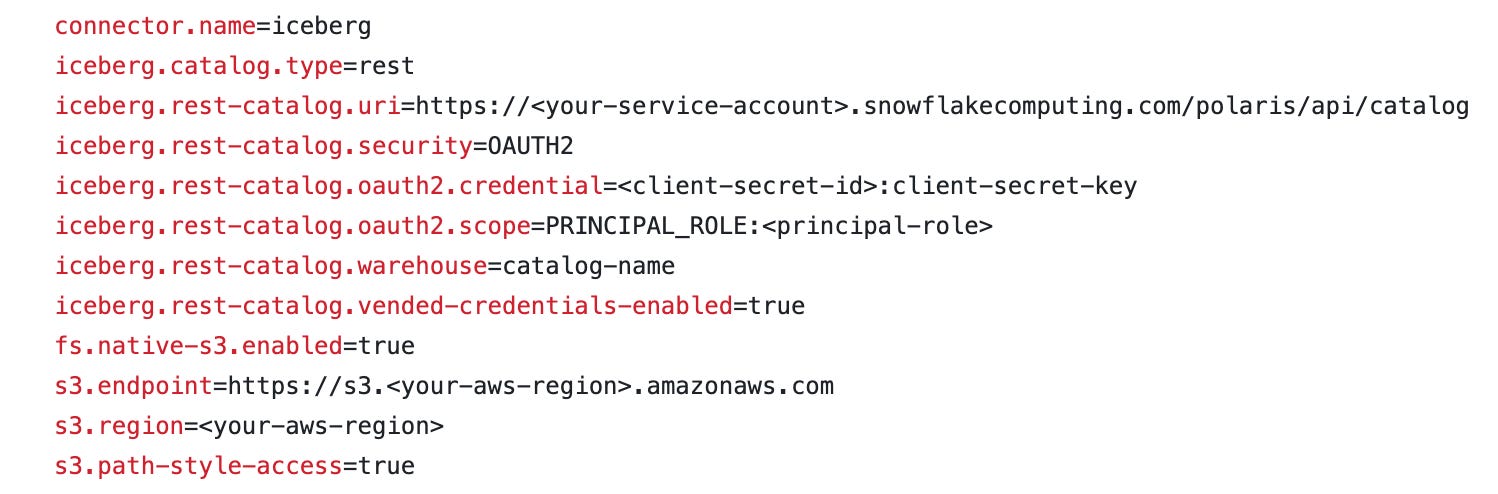
Update the properties with your catalog information
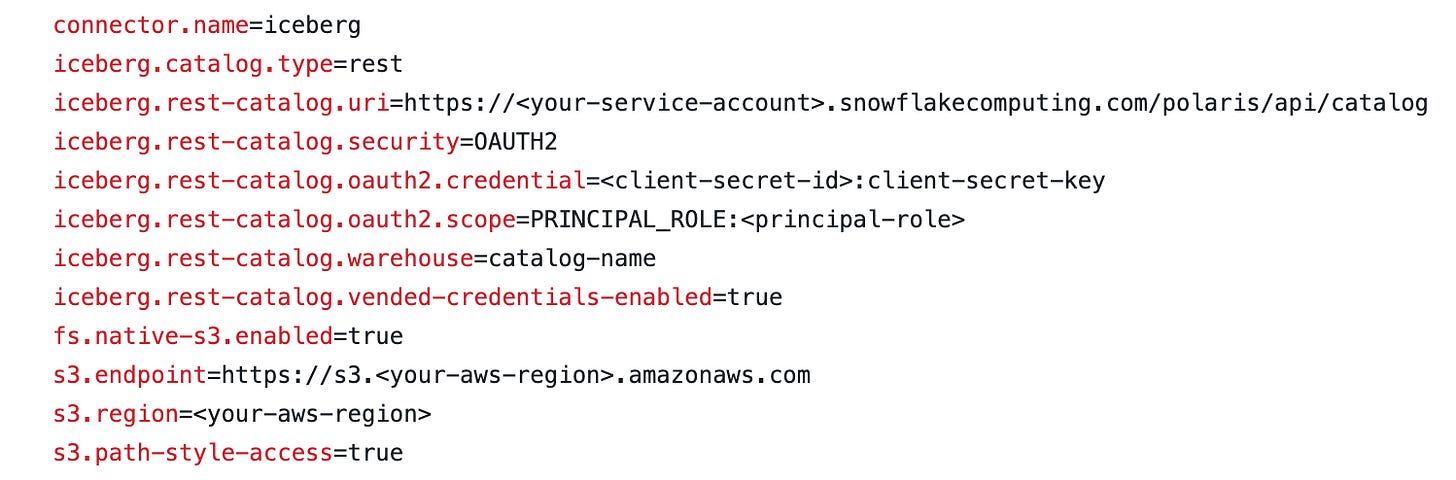
Start the Trino container
docker-compose up -d
Connect to Trino CLI
docker exec -it trinocontainer-trino-1 trino
Run queries
SHOW SCHEMAS FROM iceberg;
SELECT * FROM iceberg.`namespace`.`tablename` LIMIT 15;
5️) Clean Up
Done testing? Tear it all down with a few Terraform destroy commands and a quick container stop. No cloud resource scavenger hunt required.
Stop Trino
cd trinocontainer
docker-compose down
Manually Destroy Snowflake Open Catalog
Destroy AWS Terraform
cd terraform/aws_setup
terraform destroy
Destroy Aiven Terraform
terraform destroy
How This Beats the Old Way
The “before” pipeline is a mess of batch jobs, staging stores, and long waits.
The “after” pipeline is a straight shot: Kafka → Iceberg → Query.
Try It Yourself
Clone the repo, watch the video, and try it out yourself.
You’ll see your first events appear in Iceberg tables — query-ready within seconds.
 | A guest post by
|